storm and jstorm
Hadoop与Storm比较
1.Storm用于实时计算,Hadoop用于离线计算。
2.Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。
3.Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
4.Storm与Hadoop的编程模型相似。
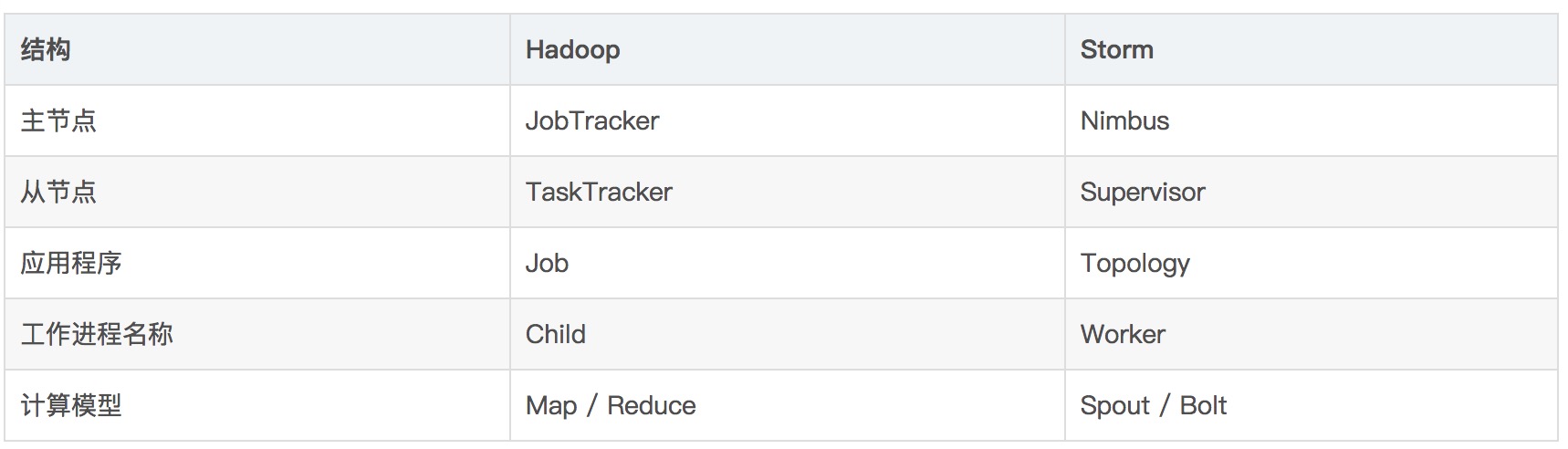
Storm架构
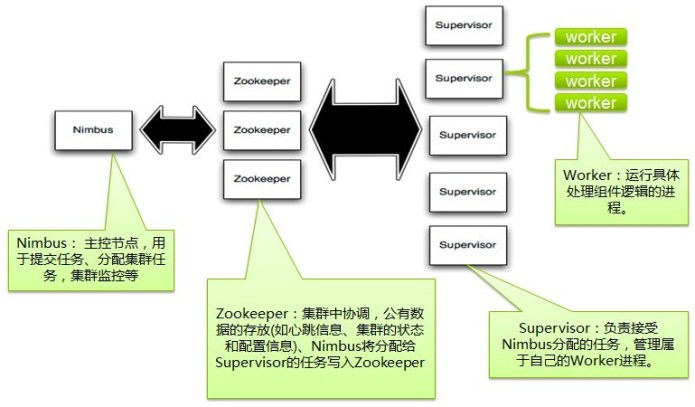
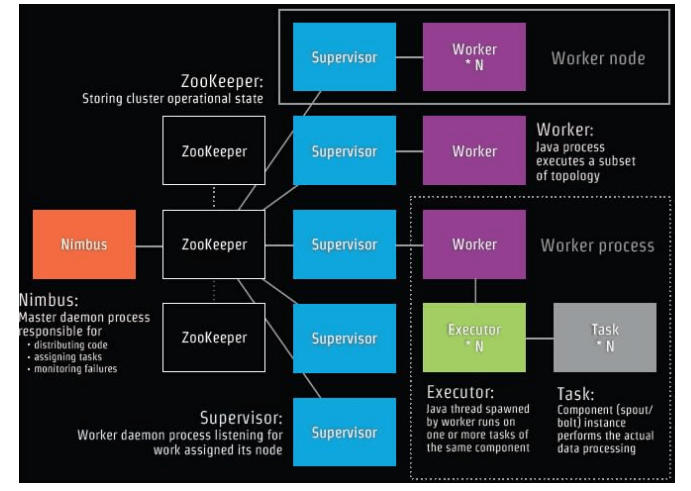
Nimbus
Storm集群的Master节点,负责分发用户代码,指派给具体的Supervisor节点上的Worker节点,去运行Topology对应的组件(Spout/Bolt)的Task。
Supervisor
Storm集群的从节点,负责管理运行在Supervisor节点上的每一个Worker进程的启动和终止。通过Storm的配置文件中的supervisor.slots.ports配置项,可以指定在一个Supervisor上最大允许多少个Slot(各个节点上的资源被抽象成粗粒度的slot,有多少slot就能同时运行多少task),每个Slot通过端口号来唯一标识,一个端口号对应一个Worker进程(如果该Worker进程被启动)。
Worker
运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task
worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
ZooKeeper
用来协调Nimbus和Supervisor,如果Supervisor因故障出现问题而无法运行Topology,Nimbus会第一时间感知到,并重新分配Topology到其它可用的Supervisor上运行
Storm编程模型

1. Storm:中运行的一个实时应用程序的名称。将Spout、Bolt整合起来的拓扑图。定义了Spout和Bolt的结合关系、并发数量、配置等等。
2. Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
3. Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
4. Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
5. Stream:Tuple的集合。表示数据的流向。
Topology
在Storm中,一个实时应用的计算任务被打包作为Topology发布,这同Hadoop的MapReduce任务相似。但是有一点不同的是:在Hadoop中,MapReduce任务最终会执行完成后结束;而在Storm中,Topology任务一旦提交后永远不会结束,除非你显示去停止任务。计算任务Topology是由不同的Spouts和Bolts,通过数据流(Stream)连接起来的图。一个Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
1. Worker(进程)
2. Executor(线程)
3. Task
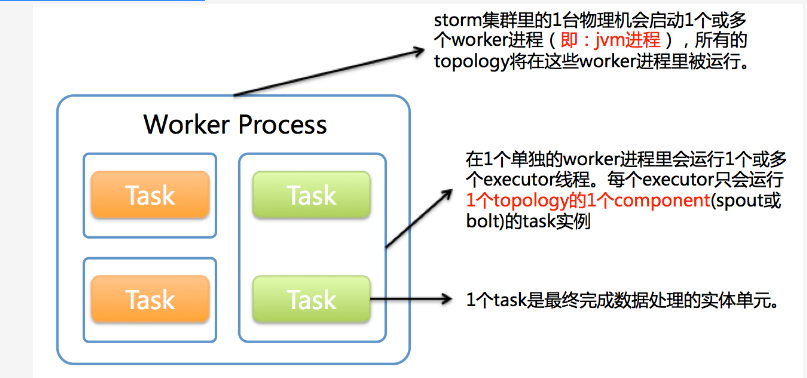
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
storm所有的元数据信息保存在Zookeeper中!
Storm Streaming Grouping
stream Grouping ,告诉topology如何在两个组件之间发送tuple。
1. Shuffle Grouping :随机分组,尽量均匀分布到下游Bolt中,来自Spout的输入将混排,或随机分发给此Bolt中的任务。对各个task的tuple分配的比较均匀。
2. Fields Grouping :按字段分组,按数据中field值进行分组;相同field值的Tuple被发送到相同的Task,相同field值的tuple会去同一个task,这对于WordCount来说非常关键。
3. All grouping :广播, 对于每一个tuple将会复制到每一个bolt中处理。
4. Global grouping :全局分组,Tuple被分配到一个Bolt中的一个Task,实现事务性的Topology。Stream中的所有的tuple都会发送给同一个bolt任务处理,所有的tuple将会发送给拥有最小task_id的bolt任务处理。
5. None grouping :不分组,不关注并行处理负载均衡策略时使用该方式,目前等同于shuffle grouping,另外storm将会把bolt任务和他的上游提供数据的任务安排在同一个线程下。
6.Direct grouping :直接分组 指定分组
JStorm
- storm的核心基本都是使用clojure语言实现的,JStorm用Java完全重写了Storm内核, 是基于Storm的二次开发产物,用户可以无缝将应用从Storm迁移到JStorm。
- jstorm设计来自storm底层实现原理,又同时优化了一些关键点实现,比如实现Nimbus HA;
- Storm1.0也借鉴了JStorm实现,对之前版本做了大量优化,Storm2.0将会基于JStorm。
- 就使用而言,二者在API层基本都一致,学会一个,转换到另一个,会比较自然。
参考博文:https://blog.csdn.net/weiyongle1996/article/details/77142245?utm_source=gold_browser_extension; https://www.cnblogs.com/zlslch/p/6628693.html