hdfs
HDFS写入操作
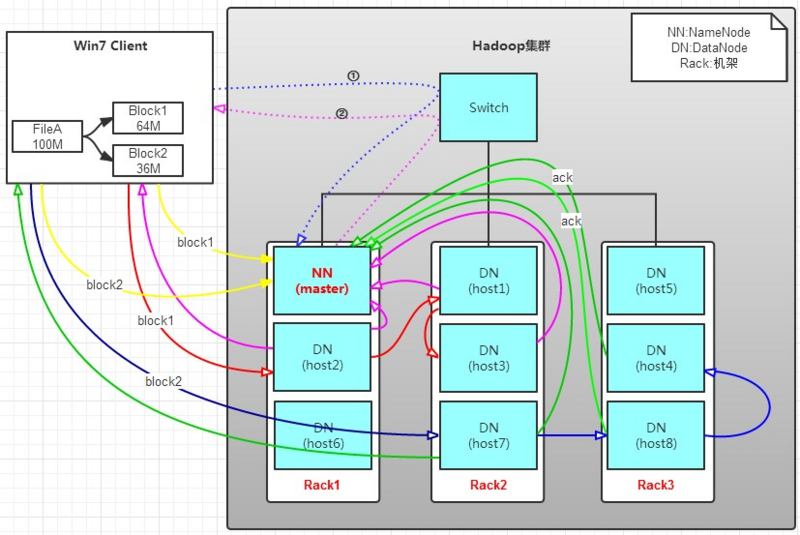
场景
1.有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
2.HDFS按默认配置。
3.HDFS分布在三个机架上Rack1,Rack2,Rack3。
写操作流程
1.将 100M 文件划分为 64M 和 36M 两个block
2.将 64M 的block1按 64k 的package划分;
3.将第一个package发送给host2;
4.host2接收完后,将第一个package发送给host1,同时client向host2发送第二个package;
5.host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package;
6.以此类推,如图红线实线所示,直到将block1发送完毕;
7.host2、host1、host3向NameNode发送通知,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。(ack)
8.client收到host2发来的消息后,向namenode发送消息,说block1写完了。这样block1就完成了。如图黄色粗实线;
9.同样的方式向host7,host8,host4发送block2
写操作总结
1. 写1T文件,我们需要3T的存储,3T的网络流量贷款。
2. 在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
3. 挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
HDFS读取操作
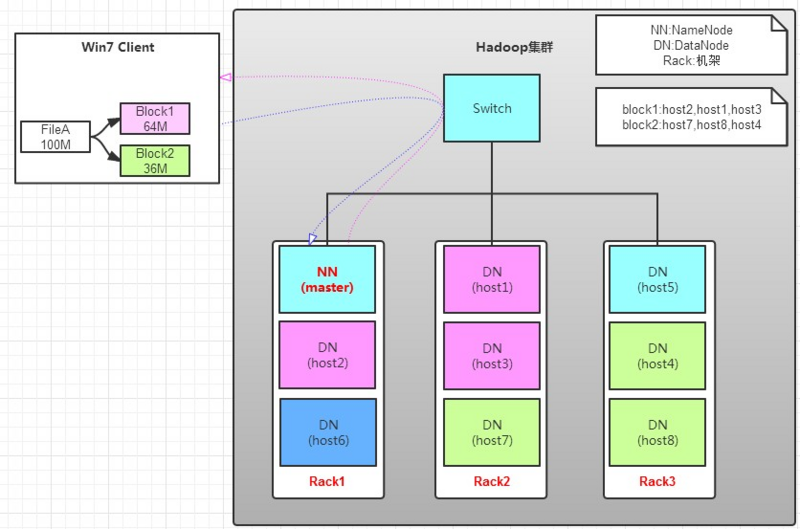
场景
1.client要从datanode上,读取FileA。而FileA由block1和block2组成。
读操作流程
1.client向namenode发送读请求;
2.namenode查看Metadata信息,返回fileA的block的位置。
3.client读取block数据,先block1,再block2
读操作总结
1.如果clinet位于机架上,优选读取本机架上的数据;
2.namenode读取的block元数据列表是按照Datanode的网络拓扑结构进行排序过的(本地节点优先,其次是同一机架节点);
3.Client还维护了一个dead node列表,只要此时bock对应的Datanode列表中节点不出现在dead node列表中就会被返回,用来作为读取数据的Datanode节点。
参考文章:https://segmentfault.com/a/1190000011575458;
https://www.cnblogs.com/YDDMAX/p/6753591.html