大数据知识点整理
1.Hadoop
1.简述如何安装配置apache 的一个开源的hadoop
1 ) 安装JDK并配置环境变量(/etc/profile)
2) 关闭防火墙
3) 配置hosts文件,方便hadoop通过主机名访问(/etc/hosts)
4) 设置ssh免密码登录
5) 解压缩hadoop安装包,并配置环境变量
6) 修改配置文件( $HADOOP_HOME/conf )
hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml
包括:namenode、secondarynamenode通信地址,hdfs副本数量,mapreduce使用framework(yarn),yarn的resourcemanager等
7) 格式化hdfs文件系统 (hadoop namenode -format)
8) 启动hadoop ( $HADOOP_HOME/bin/start-all.sh )
9) 使用jps查看进程
详情:https://www.linuxidc.com/Linux/2017-03/142051.htm
2.列出hadoop集群中的都分别需要启动哪些进程,及其作用
1.Namenode:维护元数据信息,当jobClient进行读写请求的时候,返回block和datanode的位置信息。
2.SecondaryNameNode:协助namenode进行元数据的合并,一定范围内的数据备份。
3.Datanode:存储数据,向namenode发送心跳报告,接收namenode节点的指令以及Block副本的复制
4.ResourceManager:在yarn中,resourceManager负责集群中所有资源的统一管理和分配,接收来自各个节点的资源回报信息,并把这些信息按照一定的策略分配给各个应用程序。
5.NodeManager:是yarn中每个节点上的代理,他管理hadoop集群中单个计算节点包括与resourcesManager保持通信,监督Container的生命周期管理,监控每个Container的资源使用情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务。
在1.x版本中是Jobtracker:管理任务,并将任务分配给taskTracker
Taskreacker:任务的执行方。
3.简述mapreduce的运行原理
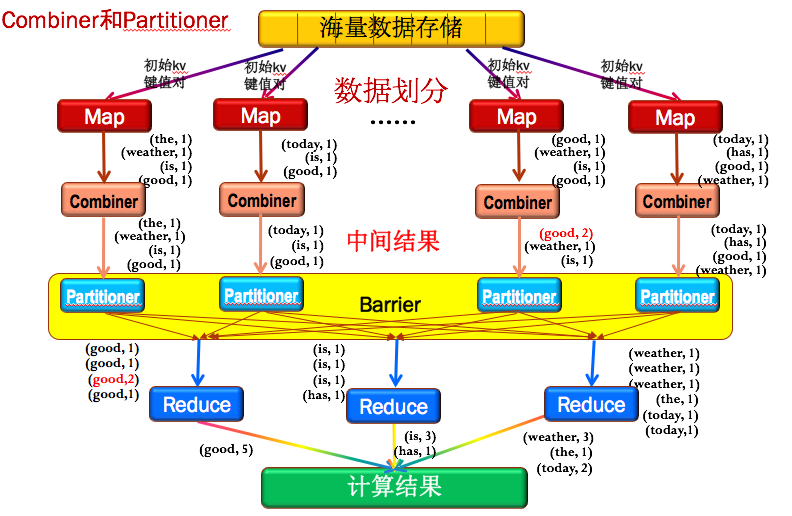
Combiner可以理解为一个小的Reduce,就是把每个Map的结果,先做一次整合;
Partitioner为了保证所有的主键相同的key值对能传输给同一个Reduce节点.
4.hive中内部外部表的区别
1.未被external修饰的是内部表,被external修饰的为外部表;
2.内部表数据由Hive自身管理,外部表数据由HDFS管理;
3.内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定;
4.删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
5.mapreduce中的combiner和partition的区别
1.partition
分割map每个节点的结果,按照key分别映射给不同的reduce,可以自定义;
默认使用哈希函数来划分分区,HashPartitioner是mapreduce的默认partitioner。
HashPartitioner计算方法是which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。
当map输出的时候,写入缓存之前,会调用partition函数,计算出数据所属的分区,并且把这个元数据存储起来。
当数据达到溢出的条件时,读取缓存中的数据和分区元数据,然后把属与同一分区的数据合并到一起。
2.combiner
计算规则与reduce一致(在map端做);
combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,因为combine本质上就是reduce操作;
详细:https://blog.csdn.net/yangjjuan/article/details/78119399
6.跨集群数据同步distcp的原理
1.hadoop distcp –m 10 hdfs://namenodeA/data/weblogs hdfs://namenodeB/data/ weblogs
2.文件夹中的内容将被复制为一个临时的大文件,这些文件内容的拷贝工作被分配给多个map任务
3.将会启动一个只有map的MapReduce作业来实现两个集群间的数据复制。默认情况下,每个map就将会分配到一个256MB的数据块文件
7.描述mapreduce的过程,中间有几次写磁盘
1.spill:
map过程中将Kvbuffer(Kvmeta存放索引,索引会根据partition和key排序)中的数据达到spill阈值
(如80%)后从所有的本地目录中轮训查找能存储这么大空间的目录,创建一个类似于 “spill12.out”的文件
Spill线程根据排过序的Kvmeta挨个把partition的数据吐到这个文件中,直到把所有的partition遍历完
同时创建一个“spill12.out.index”文件存索引信息;这些文件很多的话会被Merge成少量文件。
2.cpoy:
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据,拖一个Map数据过来就会创建一个文件;
有些Map的数据较小放在内存中,有些Map的数据大放在磁盘上,最后会进行一个全局合并(磁盘、内存均可能)。
3.reduce:
根据reduce任务内容操作数据后落到hdfs上。
详情:https://blog.csdn.net/ebay/article/details/45722263 https://blog.csdn.net/mrlevo520/article/details/76781186
8.ORC、Parquet等列式存储的优点
1.查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
2.由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
3.由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
详情:https://blog.csdn.net/yu616568/article/details/51868447/
9.hive倾斜原因,怎么解决,mapjoin
1.map端生成的key分布不均匀
2.一般join:
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,
用于标明此value对应哪个表;按照key进行排序
3.mapjoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,而普通的
equality join则是类似于mapreduce模型中的file join,需要先分组,然后再reduce端进行连接;
由于mapjoin是在map是进行了join操作,省去了reduce的运行,效率也会高很多
详情:http://lxw1234.com/archives/2015/06/313.htm https://blog.csdn.net/liuxiao723846/article/details/78739097
10.mapreduce二次排序
(待补充)
2.Spark
1.RDD中reduceBykey与groupByKey的区别
1.reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。
这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
2.groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),此操作发生在reduce端,所以势必会将所有
的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成OutOfMemoryError。
详情:https://www.cnblogs.com/0xcafedaddy/p/7625358.html
3.Yarn
1.对yarn的理解
1.hadoop https://www.cnblogs.com/cxzdy/p/5494929.html
2.spark https://wyk2011fj.github.io/2018/07/yarn/
4.Redis
1.Redis性能优化,单机增加CPU核数是否会提高性能
1.单一线程也只能用到一个cpu核心,可以在同一个多核的服务器中,可以启动多个实例,
组成master-master或者master- slave的形式,耗时的读命令可以在slave进行
2.rdb(快照持久化):Redis主进程fork出一个子进程,持久化工作由子进程完成
Redis crash掉之后,重启时能够自动恢复到上一次RDB快照中记录的数据。
优点:对性能影响最小;
容灾;
进行数据恢复比使用AOF要快很多。
缺点:定点,会丢数据;
如果cpu不够强(比如单核CPU),Redis在fork子进程时可能会消耗较长的时间(长至1秒),影响客户端请求。
3.AOF:Redis会把每一个写请求都记录在一个日志文件里。
在Redis重启时,会把AOF文件中记录的所有写操作顺序执行一遍,确保数据恢复到最新
AOF默认是关闭的,可自行配置(随时;1秒一次;系统决定)
优点:安全,数据丢失少
断电等,日志没写全,redis-check-aof工具可修复
AOF文件易读,可修改(错误操作时)
缺点:AOF文件通常比RDB文件更大
性能消耗比RDB高
数据恢复速度比RDB慢
4.pipelining:实现在一次交互中执行多条命令
只需要从客户端一次向Redis发送多条命令(以\r\n)分隔,Redis会依次执行这些命令,
并且把每个命令的返回按顺序组装在一起一次返回
缺点:只能用于执行连续且无相关性的命令,当命令的生成依赖于前一命令的返回时,就无法使用了。
详情:https://www.cnblogs.com/276815076/p/7245333.html
5.kafka
1.采集数据为什么选择kafka
1.同时为发布和订阅提供高吞吐量(多消费者)。
2.可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费。
3.分布式系统,易于向外扩展。
4.消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
5.支持online和offline的场景。
原理:https://wyk2011fj.github.io/2018/10/Kafka/
6.Sqoop
1.datax的架构,为什么不用sqoop
1.sqoop:主要服务于关系型数据库和HDFS之间数据传输
https://wyk2011fj.github.io/2018/08/sqoop/
2.datax:DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,
实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换。
DataX插件分为Reader和Writer两类。Reader负责从数据源端读取数据到Storage(交换空间);
Writer负责将Storage中的数据写入到数据目的端。
Storage可以适配不同种类的Reader和Writer,从而实现数据同步.
DataX每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行;
单机多线程执行模型可以让DataX速度随并发成线性增长。
7.Java
1.ArraryBlockingQueue的实现
1.Java并发包中的阻塞队列一共7个,他们都是线程安全的。
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
DealyQueue:一个使用优先级队列实现的无界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
2.其安全性的保证是由ReentrantLock保证的
3.ReentrantLock:重入锁(递归锁)、显示锁、排他锁(独占锁)
4.详情:
https://www.cnblogs.com/yulinfeng/p/6986975.html
2.JVM参数调优经验
1.https://blog.csdn.net/jisuanjiguoba/article/details/80176223
8.ZK
1.zookkeeper HA原理
1.HA:高可用,High Availability
2.https://wyk2011fj.github.io/2018/07/zookper/
9.数据结构及算法
1.大顶堆、小顶堆;堆的建堆过程,调整过程
1.堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;
或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
2.堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。
3.堆排序的平均时间复杂度为 Ο(nlogn)。
4.步骤:创建一个堆 H[0……n-1];
把堆首(最大值)和堆尾互换;
把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
重复步骤 2,直到堆的尺寸为 1。
5.java实现:

2.排序算法
1.https://www.cnblogs.com/onepixel/articles/7674659.html
3.二分法以及变种
1.二分查找就是将查找的键和子数组的中间键作比较,如果被查找的键小于中间键,
就在左子数组继续查找;如果大于中间键,就在右子数组中查找,否则中间键就是要找的元素。
2.数组之中的数据可能可以重复,要求返回匹配的数据的最小(或最大)的下标;
更近一步,需要找出数组中第一个大于key的元素(也就是最小的大于key的元素的)下标,等等。
3.一般在判断中间值后,再做一次判断(如左移,右移等)
https://blog.csdn.net/iluojie/article/details/81273631
N.其他
1.项目中遇到什么难题
1.https://wyk2011fj.github.io/2018/11/spark%E5%B0%8F%E6%96%87%E4%BB%B6%E8%BF%87%E5%A4%9A%E9%97%AE%E9%A2%98%E8%AE%B0%E5%BD%95/
2.讲一讲checkpoint
1.spark:防止计算失败后从头开始计算造成的大量开销,RDD会checkpoint计算过程的信息,
这样作业失败后从checkpoing点重新计算即可,提高效率。
2.写:当RDD的action算子触发计算结束后会执行checkpoint。
3.读:task计算失败的时候会从checkpoint读取数据进行计算。
4.分类:LocalRDDCheckpointData:临时存储在本地executor的磁盘和内存上;
特点是快,适合lineage信息需要经常被删除的场景,可容忍executor挂掉。
ReliableRDDCheckpointData:存储在外部可靠存储(如hdfs);
可以达到容忍driver挂掉情况。虽然效率没有存储本地高,但是容错级别最好。
如果代码中没有设置checkpoint,则使用local模式,如果设置路径,则使用reliable模式
3.调度系统的实现,开源调度系统Azkaban
1.简介:Azkaban是由Linkedin开源的一个批量工作流任务调度器
2.组成:关系型数据库(MySQL);AzkabanWebServer;AzkabanExecutorServer
3.关系型数据库:存储状态,流程,计划,日志,路径等信息
4.AzkabanWebServer:整个Azkaban工作流系统的主要管理者;
负责project管理、用户登录认证、定时执行工作流、跟踪工作流执行进度等一系列任务。
提供Web服务操作的接口,利用该接口,用户可执行登录、创建project、上传workflow、
执行workflow、查询workflow的执行进度、杀掉workflow等一系列操作。
Azkaban使用以.job文件定义流中任务,用dependencies属性定义依赖关系。
这些作业文件和关联的代码最终以*.zip的方式通过Azkaban UI上传到Web服务器上。
5.AzkabanExecutorServer:负责具体的工作流的提交、执行,可以启动多个执行服务器,
通过mysql数据库来协调任务的执行。
4.有没有数据丢失,怎么解决
1.kafka数据丢失:
消费丢失:数据回放,即换个groupid重新消费数据(只消费在zookeeper注册过之后产生的数据);
一样,说明消费端或者传输过程中,没有发生丢失。
生产丢失:可能为数据量过大,网络繁忙,带宽不足,网络不稳定,中断;
配置消息重试的机制,默认1秒过短;
//producer用于压缩数据的压缩类型。默认是无压缩。正确的选项值是none、gzip、snappy。
压缩最好用于批量处理,批量处理消息越多,压缩性能越好
props.put("compression.type", "gzip");
//增加延迟
props.put("linger.ms", "50");
//这意味着leader需要等待所有备份都成功写入日志,
这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。
props.put("acks", "all");
//设置大于0的值将使客户端重新发送任何数据,一旦这些数据发送失败。
注意,这些重试与客户端接收到发送错误时的重试没有什么不同。
允许重试将潜在的改变数据的顺序,如果这两个消息记录都是发送到同一个partition,
则第一个消息失败第二个发送成功,则第二条消息会比第一条消息出现要早。
props.put("retries ", 30);
props.put("reconnect.backoff.ms ", 20000);
props.put("retry.backoff.ms", 20000);
producer.type:
0---表示不进行消息接收是否成功的确认;
1---表示当Leader接收成功时确认;
-1---表示Leader和Follower都接收成功时确认;
request.required.acks:
acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
详情:https://blog.csdn.net/u012050154/article/details/78592854