Java知识点整理
常见Java知识点及答案
1.Java设计模式
1.java的设计模式大体上分为三大类:
创建型模式(5种):工厂方法模式,抽象工厂模式,单例模式,建造者模式,原型模式。
结构型模式(7种):适配器模式,装饰器模式,代理模式,外观模式,桥接模式,组合模式,享元模式。
行为型模式(11种):策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、
备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
2.工厂模式(Factory Method)
常用的工厂模式是静态工厂,利用static方法,作为一种类似于常见的工具类Utils等辅助效果,
一般情况下工厂类不需要实例化。

3.抽象工厂模式(Abstract Factory)
新增子工厂类实现新增产品,无需改动原有代码。

4.单例模式(Singleton)
在内部创建一个实例,构造器全部设置为private,所有方法均在该实例上改动,
在创建上要注意类的实例化只能执行一次,可以采用许多种方法来实现,
如Synchronized关键字,或者利用内部类等机制来实现。

5.建造者模式(Builder)
一般用于实体类(bean)部分赋值后返回使用。

6.代理模式(Proxy)
客户端通过代理类访问,代理类实现具体的实现细节,客户只需要使用代理类即可实现操作,
如Spring里的AOP等。
原文:https://www.cnblogs.com/malihe/p/6891920.html
2.Java内存模型
Java内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样底层细节。
经常有人把Java内存区分为堆内存(Heap)和栈内存(Stack),这种分法比较粗糙,Java内存区域的划分实际上远比这复杂。
1.Java虚拟机内存模型中定义的访问操作;
(这里的主内存、工作内存与Java内存区域的Java堆、栈、方法区不是同一层次内存划分)
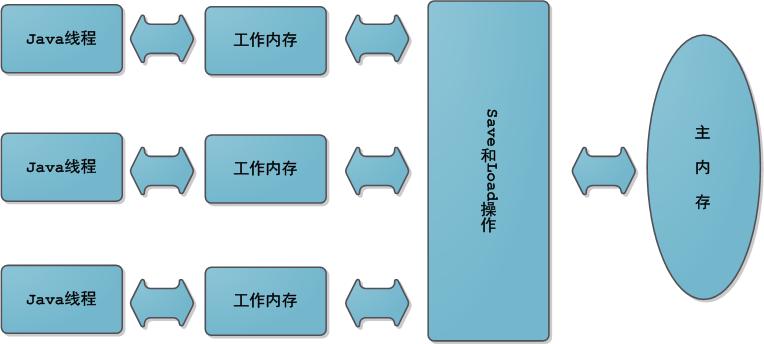
2.JVM的逻辑内存模型:
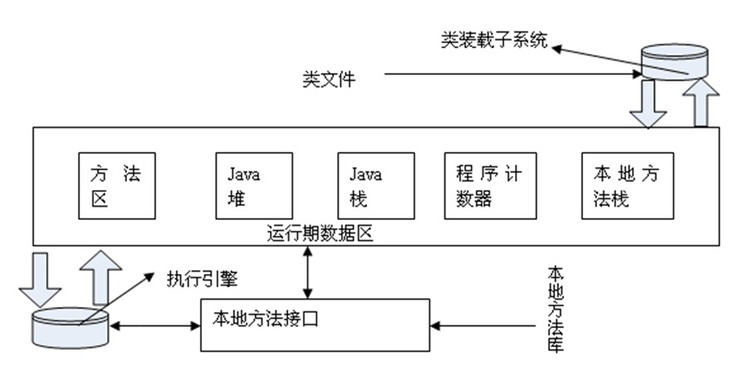
2.1 Java堆
一般是Java虚拟机所管理的内存中最大的一块;
被所有线程共享的一块内存区域,在虚拟机启动时创建;
唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存;
堆也无法再扩展时,将会抛出OutOfMemoryError异常。
2.2 Java栈
线程私有,生命周期与线程相同;
方法被执行的时候都会创建一个栈帧用于存储局部变量表、操作栈、动态链接、方法出口等信息;
方法被调用直至执行完成的过程,对应着栈帧在虚拟机栈中从入栈到出栈的过程;
局部变量表存放了编译期可知的基本数据类型、对象引用、returnAddress类型;
进入方法时,这个方法需要在帧中分配多大的局部变量空间是确定的,且运行期间不变;
如果线程请求的栈深度大于虚拟机所允许的深度,抛出StackOverflowError异常;
如果虚拟机栈可以动态扩展,当扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
2.3 方法区
与Java堆一样,被各个线程共享;
存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据;
Java虚拟机规范将其描述为堆的一个逻辑部分,却有别名Non-Heap(非堆),说明还是有所区分;
方法区无法满足内存分配需求时,抛出OutOfMemoryError异常。
2.4 本地方法栈
与Java栈相似,但只为Native方法服务;
也会抛出StackOverflowError和OutOfMemoryError异常。
2.5 程序计数器
一块较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器;
为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,
各条线程之间的计数器互不影响,独立存储,称这类内存区域为“线程私有”的内存;
无OutOfMemoryError情况。
2.6 运行时常量池
方法区的一部分;
存放编译期生成的各种字面量和符号引用;
原文:https://www.cnblogs.com/dingyingsi/p/3760447.html
3.Java集合类
集合有两个基本的接口:Collection和Map。(List,Set为Collection派生的接口)
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap
1.List
1.1 ArrayList
动态数组,非线程安全,溢出扩容1.5倍,并将老数据copy到新数组中(扩容损耗资源);
1.2 Vector
同ArrayList,线程安全(所有方法加synchronized),扩容2倍(性能很差);
1.3 LinkedList
双向链表,先进先出,非线程安全
2.Set
所有Set类都不保存重复元素(Equals方法判断);
2.1 HashSet
底层通过HadhMap实现,值就是HadhMap的Key,非线程安全;
2.2 TreeSet
红黑树存储,非线程安全;
3.Map
3.1 HashMap
数据+链表,非线程安全;
3.2 LinkedHashMap
HashMap+双向链表,先进先出的HashMap,非线程安全(同时写到一个双向链表中);
3.3 HashTable
同HashMap,线程安全(synchronized),不能有null的key。
4.Spring
1.IOC
控制反转,即创建对象的控制权反转到了spring框架;
2.DI
依赖注入,Spring框架创建Bean对象时,动态的将依赖对象注入到Bean组件;
3.bean默认singleton(单例),即容器只存在单个bean实例(非线程安全);
4.bean注入方式
构造器注入,通过 <constructor-arg> 元素完成注入
setter方法注入, 通过<property> 元素完成注入
接口注入(不常用)
5.AOP
面向切面编程
6.AOP原理-代理
6.1 代理模式(java设计模式之一)
代理类与委托类有同样的接口,为委托类预处理消息、把消息转发给委托类,以及事后处理消息等;
6.2 静态代理
在编译时就已将接口,被代理类,代理类等确定下来。程序运行之前,代理类的.class文件就已经生成;
(如通过继承接口的模式预先生成代理类)
6.3 动态代理
利用Java的反射技术,在运行时创建一个实现某些给定接口的新类(动态代理类)及其实例(对象);
代理的是接口(Interfaces),不是类(Class),更不是抽象类;
6.4 Java反射机制
在运行状态中,对于任意一个类,都能够获取到这个类的所有属性和方法,对于任意一个对象,
都能够调用它的任意一个方法和属性(包括私有的方法和属性),
这种动态获取的信息以及动态调用对象的方法的功能就称为java语言的反射机制;
demo:
Class clazz1 = Class.forName("全限定类名");
User user = clazz1.getInstance();
原文:https://www.cnblogs.com/lcngu/p/5339555.html
5.数据库
事务的四个特性:
1.原子性:事务是一个不可分割的整体;
2.一致性:事务开始前和结束后,数据库的完整性约束没有被破坏;
3.隔离性:同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰;
4.持久性:事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
事务并发问题:
1.脏读:事务A读取了事务B更新的数据,然后B回滚操作,则A读取到的是脏数据(事务间可见);
2.不可重复读:事务A多次读取同一数据,事务B在此期间,对数据作了更新并提交,
导致事务A多次读取同一数据时,结果不一致;
3.幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,
但是系统管理员B就在这个时候插入了一条具体分数的记录,
当系统管理员A改结束后发现还有一条记录没有改过来,
就好像发生了幻觉一样,这就叫幻读。
其中不可重复读侧重修改,幻读侧重添加和删除
事务并发解决:
1.脏读:事务间不可见,只能读取事务开始前或者结束后的结果(但可并行);
2.不可重复读:锁行(事务操作那些行,就锁住这些行)
3.幻读:锁表(事务锁整个表)
事务隔离级别:
1.读未提交:会出现,脏读、不可重复读和幻读
2.读已提交:脏读避免,会出现,不可重复读和幻读
3.可重复读:脏读,不可重复读避免,会出现,幻读
4.串行化:均可避免
6.网络通信
RPC(Remote Procedure Call Protocol-远程过程调用);
如果有一种方式能让我们像调用本地服务一样调用远程服务,而让调用者对网络通信这些细节透明,那么将大大提高生产力,比如服务消费方在执行helloWorldService.sayHello(“test”)时,实质上调用的是远端的服务。这种方式其实就是RPC(Remote Procedure Call Protocol),在各大互联网公司中被广泛使用,如阿里巴巴的hsf、dubbo(开源)、Facebook的thrift(开源)、Google grpc(开源)、Twitter的finagle(开源);
RPC一般流程:
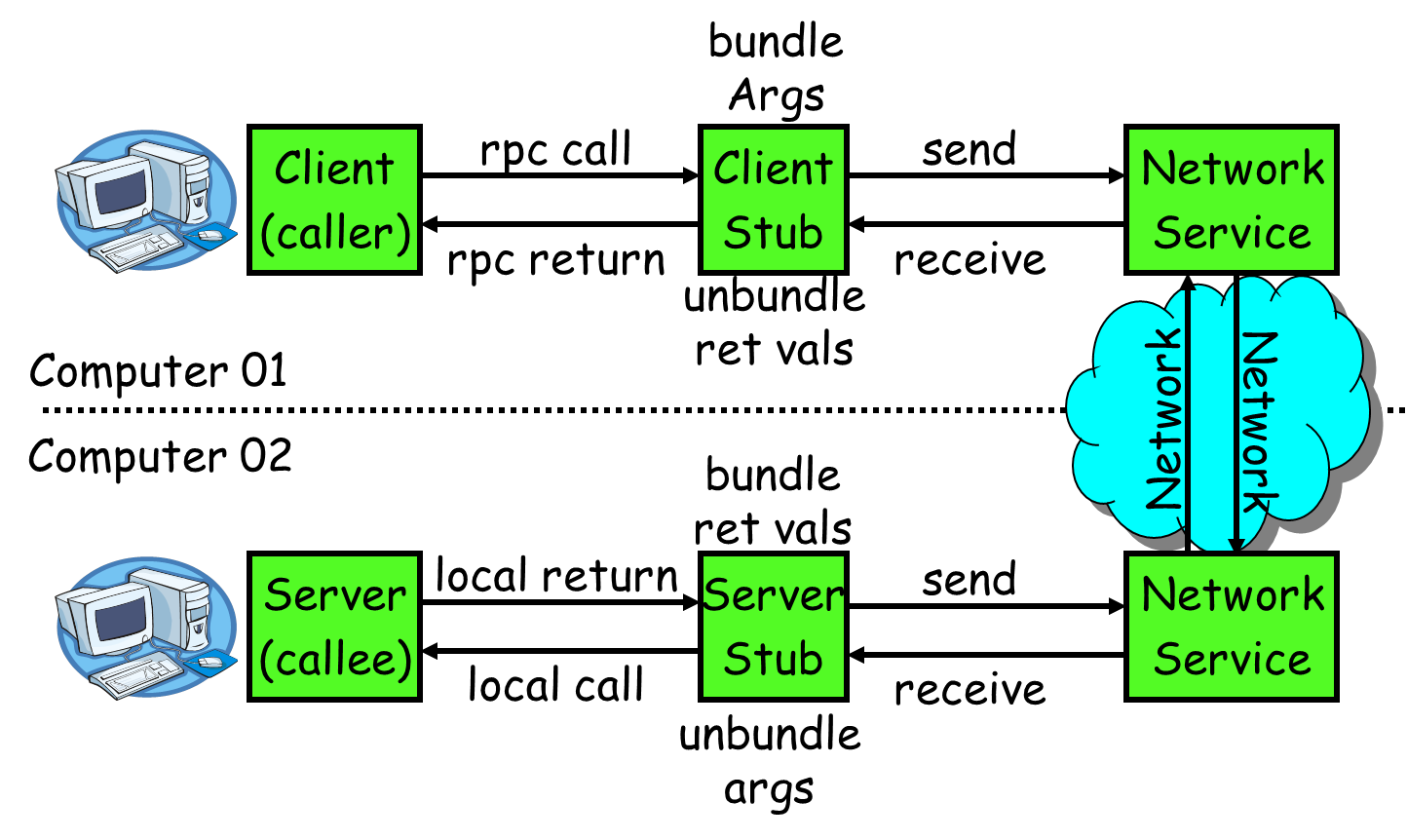
1.服务消费方(client)调用以本地调用方式调用服务;
2.client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
3.client stub找到服务地址,并将消息发送到服务端;
4.server stub收到消息后进行解码;
5.server stub根据解码结果调用本地的服务;
6.本地服务执行并将结果返回给server stub;
7.server stub将返回结果打包成消息并发送至消费方;
8.client stub接收到消息,并进行解码;
9.服务消费方得到最终结果。
RPC服务的目标就是要2~8这些步骤都封装起来,让用户对这些细节透明。
RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层;
TCP VS UDP
1.TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接;
2.TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达,
UDP尽最大努力交付,即不保证可靠交付;
3.UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性有较高的通信或广播通信;
4.每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信;
5.TCP对系统资源要求较多,UDP对系统资源要求较少。
TCP三次握手:
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;
SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),
即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),
此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
dubbo原理:
大概:使用动态代理,获取服务的方法,并且将网络通信代码封装在动态代理类的invoke方法中;
注册服务:生成代理实例,并且通过一定网络传输协议(Dubbo协议,RMI协议等)暴露给IP+端口(暴露服务);
消费服务:首先ReferenceConfig类的init方法调用Protocol的refer方法生成Invoker实例。接下来把Invoker转为客户端需要的接口即可。 \;
dubbo启动过程:
1.暴露服务到本地
2.暴露服务到远程
3.启动netty服务
4.连接zookeeper
5.注册服务到zookeeper
6.监听zookeeper中消费服务
Dubbo相关协议:
Dubbo 允许配置多协议,在不同服务上支持不同协议或者同一服务上同时支持多种协议。
不同服务在性能上适用不同协议进行传输,比如大数据用短连接协议,小数据大并发用长连接协议。
dubbo:
Dubbo 缺省协议是dubbo协议,采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,
以及服务消费者机器数远大于服务提供者机器数的情况。
反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
rmi:
RMI协议采用阻塞式(同步)短连接和 JDK 标准序列化方式。
适用范围:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件。
hessian:
Hessian底层采用Http通讯(同步),采用Servlet暴露服务。
适用于传入传出参数数据包较大,提供者比消费者个数多,提供者压力较大,可传文件。
其他:http, webservice, thrift, memcached, redis
原文: http://www.importnew.com/22003.html(RPC介绍很详细有空要细看下)
7.原生类
Java中,数据类型分为基本数据类型(或叫做原生类、内置类型)和引用数据类型。
Java不是纯的面向对象的语言,不纯的地方就是这些基本数据类型不是对象。
如果想编写纯的面向对象的程序,用包装器类是取代基本数据类型就可以了。
六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。
基本类型的存储空间:
基本知识:
bit(位)
byte(字节)
1byte=8bit
数字型:
byte--8位(1字节), -128(-2^7) 至 127(2^7-1)
short--16位(2字节), -32768(-2^15) 至 32767(2^15-1)
int--32位(4字节), (-2^31) 至 (2^31 - 1)
long--64位(8字节), (-2^63) 至 (2^63 -1)
浮点型:
float--32位(4字节),
double--64位(8字节),
布尔型:
boolean--1位
字符型:
char--单一的 16 位 Unicode 字符;(2字节)
最小值是 \u0000(即为0);最大值是 \uffff(即为65,535);
char 数据类型可以储存任何字符;
这六种数字类型都是有符号的。固定的存储空间正是Java可移植性、跨平台的原因之一;
基本类型的存在导致了Java OOP的不纯粹性。因为基本类型不是对象,一切皆对象是个小小的谎言。
原文: https://blog.csdn.net/wangshuai6707/article/details/12174471
N.其他
1.String、StringBuilder、StringBuffer三者的区别
运行速度:StringBuilder > StringBuffer > String;
String为字符串常量,另两个为字符串变量,即String对象创建之后不可改,变量是可以更改的;
StringBuffer使用synchronized,线程安全,而StringBuilder非线程安全;
原文:https://blog.csdn.net/peterzhihua/article/details/71260811 https://www.cnblogs.com/su-feng/p/6659064.html