机器学习基本概念
什么是机器学习
机器学习是一种让计算机利用数据而不是指令来进行各种工作的方法,主要使用归纳、综合而不是演绎。
它研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
demo:

机器识别图片结果为:“A person riding a motorcycle on a dirt road”
相关概念
数据集:数据的集合
训练集:用来进行训练,也就是产生模型或者算法的数据集
测试集:用来专门进行测试已经学习好的模型或者算法的数据集
样本:单条数据(可为训练样本或者测试样本)
特征(特征向量):属性的集合,通常用一个向量来表示,附属于一个实例
属性值:单个属性的值
标签(标记):实例类别的标记(通常为结果)
监督学习:训练集有类别标记
非监督学习:训练集无类别标记
半监督学习:有类别标记的训练集 + 无标记的训练集
分类:目标标记为类别型数据
回归:目标标记为连续性数值
聚类:非监督学习中将实例聚集成类
简单案例
假设想研究某城市的温度,湿度,风速等因素跟城市天气的关系,有如下数据:
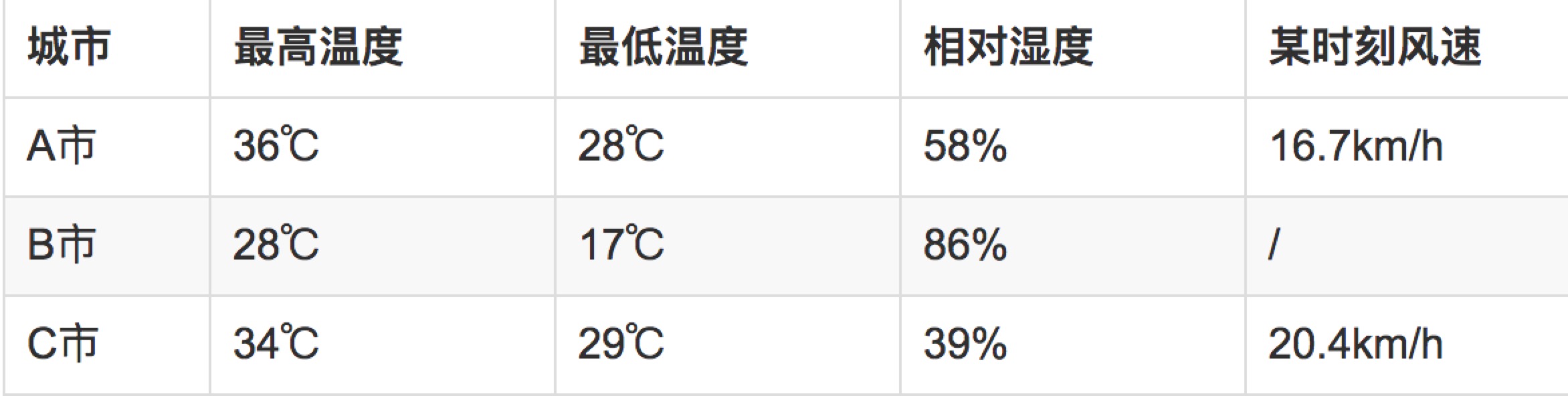
数据集:A市、B市、C市等市以及其情况的总和
单个样本:某城市和它的情况(一行数据)
特征:除了 ‘城市’ 外的每列,如最高温度、最低温度
特征值:特征的具体数值,如36℃ 、28℃
标签:城市的天气,如晴朗,阴雨(结果)
训练集:假设这里用 A市、B市、C市 数据产生模型
测试集:假设知道 D市 的温度,湿度,风速等因素,不知道天气
监督学习:知道天气的情况下,研究模型
非监督学习:不知道天气的情况下,研究模型
其他
二分类问题:
衡量结果精度的有一些相关术语,如准确率、精确率和召回率。这三个词汇应用于二分类问题:将数据分为正类和反类。
其中,
准确率:预测和标签一致的样本在所有样本中所占的比例;
精确率:预测为正类的数据中,有多少确实是正类;
召回率:所有正类的数据中,你预测为正类的数据有多少。
这三个数据往往用来衡量一个二分类算法的优劣。
回归问题:
回归问题往往会通过计算误差来确定模型的精确性。误差由于训练集和验证集的不同,会被分为训练误差和验证误差。
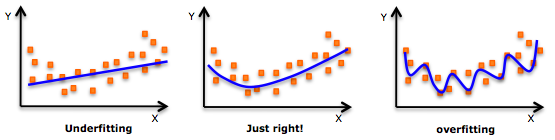
但值得注意的是,模型并不是误差越小就一定越好,因为如果仅仅基于误差,我们可能会得到一个过拟合的模型;但是如果不考虑误差,我们可能会得到一个欠拟合的模型,
比如:
聚类问题:
聚类问题的标准一般基于距离:簇内距离和簇间距离。根据常识而言,簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。
一般来说,衡量聚类问题会给出一个结合簇内距离和簇间距离的公式。
参考:
https://www.cnblogs.com/qwj-sysu/p/5940517.html https://baike.baidu.com/item/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/217599?fr=aladdin https://www.jianshu.com/p/891d71729c43 https://www.cnblogs.com/baiboy/p/ml2.html https://blog.csdn.net/zhangbijun1230/article/details/79439216