记一波数据仓库从0到1的实战经历
之前算是经历了一个团队的数据体系从比较原始的状态到相对比较完善的数据仓库的演变过程,大概记录下,有个方向和思路。
1.原始状态
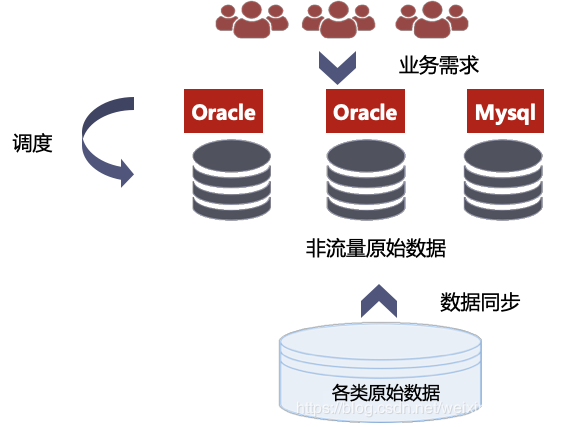
业务上
纯需求驱动,无明确分工; 根据需求,联系原数据方,通过各种技术手段得到结果。
技术上
数据存储
主要依赖oracle和mysql,绝大多数存储在oracle中。
任务调度
大部分通过可执行jar包放到服务器上起crontab任务定时执行jar包,部分写在自己的java工程里面。
数据同步
根据binlog信息,进行关系型数据库之间的数据同步。
数据产出
基本都是报表的方式,开发之间会有少量表或者接口的形式。
环境
基本不区分测试和线上环境(跟数据产出一致性要求不高有一定关系)。
问题
太多了,比如:
- 指标口径不一致,排查口径和改错成本越来越高;
- 调度任务管理难度大,需要改jar包逻辑,重新发布,且后期jar包数量惊人;
- 重复逻辑很多,造成服务器和数据库资源的浪费;分工不明确,包括团队内部和团队之间,导致交接、责任划分、产出评估等困难;
- 重复劳动成本高,人力资源浪费,且容易出错;
- 数据同步多为oracle间全量同步,浪费数据库资源;业务增长迅速,数据量短期暴增,任务sql越来越慢,且经常出现执行异常等不稳定情况;
- 不区分测试和线上,容易跑出错误数据或者将数据库跑挂。
2.温饱阶段
针对一些不可绕过的问题做出应对,但是依旧没有形成完成的数据仓库思路。
业务上
- 人员扩充后,针对各个业务线,分出了不同的数据域;
- 各个域基本都有简单的数据分层,主要只是区分ODS和非ODS,其余各个域的区分方式都略有不同;
- 推出大量数据产出及可视化产品;
- 依旧偏业务导向。
技术上
- 采用Azkaban调度,并且配套开发生成调度包的java工程;
- 开始将部分数据量过大,且实时性要求不高的数据整体迁移到hdfs,并且调度任务采用hive的方式,产出到hive表中后,通过特定的同步任务,同步到oracle中,即将计算迁移到hive;
- 偏结果导向,各个域开发方式,采用的技术基本不设限,且不做资源度量;
- 实时和准实时流量初步实现。
Azkaban调度:

问题
总体解决了温饱,但是还没有奔小康,问题依旧不少,比如:
- 依赖模式简单,不能实现复杂依赖;
- 各个域的数据分层规范及命名规范没有统一化,导致跨域数据调用和理解存在困难;
- 数据口径问题依旧没有很好解决,各个可视化系统内的数据不一致;
- Oracle计算和存储压力越来越大,异常情况越来越多;
- 数据同步模式没有得到统一,ODS数据不规范。
3.小康阶段
开始推onedata规范,技术和业务也都完善起来。
业务上
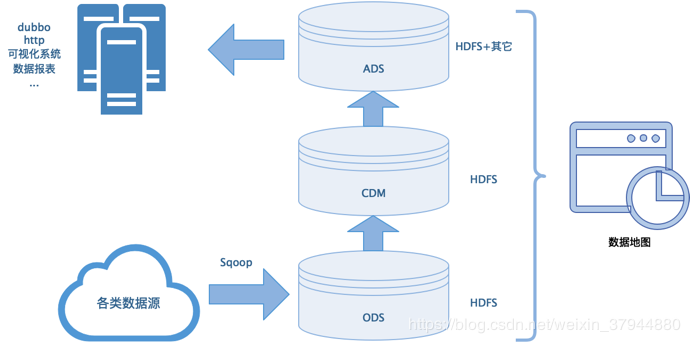
- 采用阿里的Onedata规范,将数据大致分为ods、cdm、ads三层;
- 各个域在进行细分子域(也可作为命名标准);
- 对各个数据可视化系统的数据口径做统一化,每个系统配单独口径说明文档;
- 开发指标管理系统,方便统一口径;
技术上
- 将几乎所有t+1数据迁移到hdfs上;
- 完善调度系统的功能;
- 规范所有表名、字段名,收起所有建表权限,走统一域管理员审批(为了合规);
- 自行开发任务报警和预警等功能模块(完善调度系统缺陷);
- 开发对应的数据监控系统;
- 对yarn队列进行监控,整体把控部门资源使用情况;
- 规范ODS层,统一走sqoop同步;
- 对元数据进行管理和整合,开发数据地图功能。
相对完善的架构图:
总结
- 尽量在搭建数据体系前就想好一套较完善的数据体系,一旦运行一段时间之后就很难做强制更改了(开始就要有高手带路)
- 数据出口要严格把控,一来方便统计数据价值,二来好管理口径
- 多鼓励形成规范文档,包括技术和业务的
- 不能纯需求导向,也不能完全不管需求,套用当前很流行的一句,要有”中台思想“
- 元数据其实也是很有价值的,尤其是新团队,作为衡量数据资源和任务信息,定位问题,很有价值
这篇写的也比较敢,只是有介绍了个大概的演变方向,以后有时间再完善吧。